출처:https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/이 포스팅은 Interview에 대한 대답 용도로 핵심부분만 요약해서 올린 포스팅입니다.
그러므로 자세한 부분은 다루지 않았고, 잘못된 부분에 대한 지적은 감사히 받겠습니다.
1. 정의
해시 테이블에 대해 설명을 하기 전에 몇 가지 단어에 대한 개념을 정리하겠습니다.
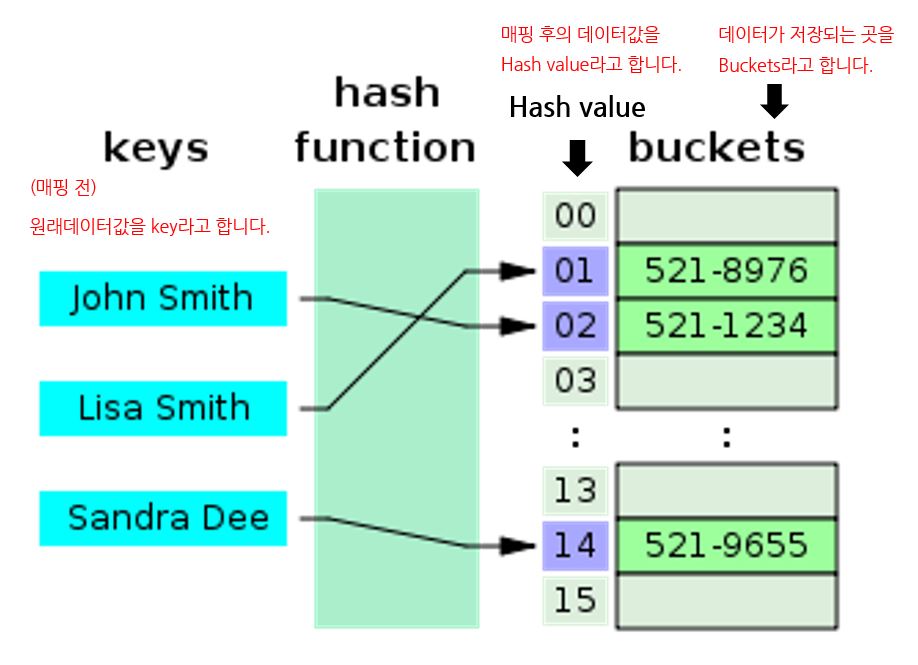
Hashing:
key를 해시값에 매핑하는 과정 자체를 의미합니다.
Hash function:
데이터의 효율적인 관리를 목적으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수
Hash Table:
해시 함수를 이용하여 key를 해시값으로 매핑하고, 이 해시값을 인덱스 혹은 주소로 삼아
데이터의 값을 key와 함께 저장하는 자료구조를 의미합니다.
2. 특징
해시테이블을 사용하는 이유는 적은 리소스로도 많은 데이터를 효율적으로 관리할 수 있기 때문입니다.
무한에 가까운 데이터를 유한개의 해시값으로 매핑해서 작은 크기의 캐시 메모리로도 프로세스를 관리할 수 있습니다.
충돌을 해결하는 방법으로는 두 가지가 존재합니다.
1) Chaining:
해당 버킷에 데이터가 있다면 링크드 리스트처럼 해당 버킷에 노드를 새로 추가하는 방식입니다.
2) Open addressing:
해당 버킷에 데이터가 있다면 비어 있는 다음 버킷에 저장하는 방식입니다.
3. 접근시간
해시테이블의 기본 연산은 삽입, 삭제, 탐색입니다.
INDEX에 해시값을 사용함으로써 모든 데이터를 살피지 않고 계산복잡성 O(1)을 지향합니다.
4. 사용분야
보안분야에서 주로 사용합니다. key와 해시값 사이에는 직접적인 연관성이 없습니다.
그러므로, 해시값만 가지고는 key값을 완전하게 복원하기 어렵기 때문입니다.